Ancova satu jalur menggunakan SPSS
![]()
Pendahuluan
Pada tulisan sebelumnya terkait Analysis of Covariance (Ancova), telah dijelaskan bahwa Ancova merupakan salah satu metode statistik gabungan dari Anova dan Regresi untuk membandingkan rata-rata antara dua atau lebih kelompok dengan mempertimbangkan pengaruh variabel bebas yang disebut sebagai covariate. Salah satu tool statistik yang dapat digunakan untuk melakukan perhitungan Ancova adalah Statistical Package for the Social Sciences (SPSS) versi 25.
Contoh deskripsi penelitian
Seorang peneliti ingin mengetahui pengaruh dari suatu Virtual Learning Environments (VLEs) terhadap prestasi belajar peserta didik pada mata kuliah Jaringan Komputer. Pengaruh tersebut dikontrol oleh suatu co-variabel (covariate) pretest. Oleh karena itu, peneliti merancang suatu penelitian eksperimen semu (quasi-experiment) dengan melibatkan kelas kontrol dan kelas eksperimen. Kelas kontrol adalah kelas yang menggunakan Virtual Learning Environments existing, contohnya menggunakan Moodle dengan suplemen video pembelajaran dan simulator Cisco-PT. Sedangkan, kelas eksperimen menggunakan Moodle dan media pembelajaran inovatif seperti Virtual Lab Network Simulation (Vilanets).
Sampai di sini, kita mengetahui ada 3 kelas dalam penelitian tersebut. Kelas ke-1 dinamakan VLE1 (VLEs dengan suplemen video), kelas ke-2 dinamakan VLE2 (VLEs dengan suplemen Cisco-PT), dan kelas ke-3 dinamakan VLE3 (VLEs dengan suplemen Vilanets). Kelas-kelas tersebut nantinya akan menjadi kelompok/dimensi di dalam variabel bebas Ancova. Jika menggunakan 3 kelas (atau lebih), maka akan ada kemungkinan perhitungan akan dilanjutkan ke post-hoc test ketika terdapat pengaruh antara VLEs dan prestasi belajar.
Karena ini adalah penelitian kuantitatif di mana tujuannya adalah menguji teori, teori baru yang diajukan harus dikonstruksi. Misalnya, peneliti ingin menguji teori VLEs. Oleh karena itu, disarankan ada teori baru turunan dari VLEs. Peneliti mengajukan teori bernama Advanced VLEs. Apabila dikaitkan dengan 3 kelas sebelumnya, dikonstruksi teori sebagai berikut. VLE1 mewakili teori Beginner VLEs, VLE2 mewakili teori Intermediate VLEs, dan VLE3 mewakili teori Advanced VLEs.
Contoh tujuan penelitian
Tujuan penelitian tersebut adalah sebagai berikut.
- Peneliti ingin menemukan pengaruh antara VLEs dan prestasi belajar yang dikontrol oleh pretest.
- Peneliti ingin menemukan perbedaan antara 3 kelompok VLEs (beginner, intermediate, dan advanced VLEs) terhadap prestasi belajar yang dikontrol oleh pretest.
Variabel-variabel dan tipe data
Variabel-variabel penelitiannya adalah sebagai berikut.
- Variabel bebas (independent variable): VLEs dengan tiga kelompok (beginner, intermediate, dan advanced VLEs), selanjutnya dinamakan VLE1, VLE2, dan VLE3. Tipe datanya adalah kategorikal di mana 1 mewakili VLE1, 2 mewakili VLE2, dan 3 mewakili VLE3.
- Variabel terikat (dependent variable): prestasi belajar (posttest). Tipe datanya adalah numerikal berkisar antara 0 - 100.
- Co-variabel (covariate): pretest. Tipe datanya adalah numerikal berkisar antara 0 - 100.
Diagram konstelasi dan hipotesis penelitian
Diagram konstelasi menunjukkan hubungan antar variabel, seperti pada Gambar 1. Hubungan tersebut memandu peneliti untuk menentukan hipotesis-hipotesis penelitian dalam rangka tercapainya tujuan-tujuan penelitian.
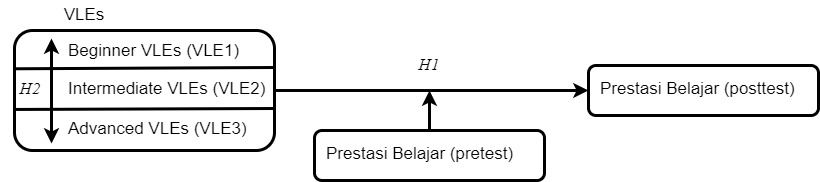

Adapun hipotesis-hipotesis penelitian adalah sebagai berikut.
- H1: Terdapat pengaruh yang signifikan VLEs terhadap prestasi belajar dikontrol oleh pretest.
- H2: Terdapat perbedaan signifikan antara VLE1, VLE2, dan VLE3 terhadap prestasi belajar dikontrol oleh pretest.
- H2.1: Terdapat perbedaan signifikan antara VLE1 dan VLE2 terhadap prestasi belajar dikontrol oleh pretest.
- H2.2: Terdapat perbedaan signifikan antara VLE1 dan VLE3 terhadap prestasi belajar dikontrol oleh pretest.
- H2.3: Terdapat perbedaan signifikan antara VLE2 dan VLE3 terhadap prestasi belajar dikontrol oleh pretest.
Inisiasi data
Buka SPSS, kemudian akan muncul 2 jendela: dataset dan output. Buka jendela dataset, kemudian konfigurasi sebagai berikut.
- Variable view:
- Name:
VLEs; Decimals:0; Values:{1, VLE1; 2, VLE2; 3, VLE3}; Measure:Nominal. - Name:
pretest; Measure:Scale. - Name:
posttest; Measure:Scale.
- Name:
- Data view: masukkan (copy/paste) data ke sel yang bersesuaian.
Download dataset:
Ubah terlebih dahulu data pada kolom VLEs mengikuti
valuespada variable view. Contoh: VLE1 ubah ke nilai1, VLE2 ubah ke nilai2, dan VLE3 ubah ke nilai3.
Dataset tersebut telah dipublikasi dan dilindungi hak cipta. Silakan digunakan sebagaimana mestinya dengan tetap melakukan sitasi apabila digunakan.
Klik di sini untuk melihat contoh tampilan inisiasi data pada SPSS.
Uji asumsi
Terdapat dua jenis uji asumsi sebelum melakukan perhitungan Ancova yakni asumsi dasar dan tambahan. Uji asumsi dasar meliputi tipe data dari masing-masing variabel, observasi yang independen antar kelompok dalam variabel bebas, dan independensi antara co-variabel dan variabel terikat. Seluruh uji asumsi dasar akan terpenuhi apabila menggunakan desain penelitian quasi-experimental pretest-posttest control group. Sedangkan uji asumsi tambahan dalam Ancova ada 5 yakni, uji asumsi outliers, linearity, homogeneity of regression slopes, normality of residuals, dan homogeneity of variances. Uji asumsi dasar dan uji asumsi tambahan wajib dipenuhi sebelum melakukan analisis Ancova guna mengurangi bias hasil penelitian. Berikut prosedur uji asumsi menggunakan SPSS terutama pada kelima uji asumsi tambahan.
Outliers
Uji asumsi yang pertama adalah outliers. Uji asumsi outliers berfungsi untuk mengidentifikasi adanya nilai-nilai ekstrim dalam dataset. Outliers memengaruhi keandalan hasil analisis Ancova, terutama terkait dengan dua asumsi utama: normalitas dan homogenitas varians. Jika terdapat outliers, distribusi data menjadi tidak normal, sehingga memengaruhi interpretasi statistik, termasuk uji Ancova. Outliers juga menyebabkan ketidakhomogenan varians antar kelompok, yang menghasilkan kesalahan dalam penentuan signifikansi hasil. Dengan mendeteksi outliers, peneliti dapat mempertimbangkan tindakan korektif, seperti transformasi data atau penggunaan metode analisis yang lebih tahan terhadap ketidaknormalan atau ketidakhomogenan varians. Oleh karena itu, uji asumsi outliers merupakan langkah penting dalam memastikan validitas dan keandalan hasil dari Ancova serta mendukung interpretasi yang akurat dari dampak variabel kovariat pada variabel terikat. Untuk melakukan uji asumsi ini pada SPSS, langkah-langkahnya adalah sebagai berikut.
Prosedur input
- Masuk ke menu SPSS
Analyze > General Linear Model > Univariate. Pada jendelaUnivariate, sesuaikan isiannya sebagai berikut.- Dependent Variable:
posttest. - Fixed Factor(s):
VLEs. - Covariate(s):
pretest.
- Dependent Variable:
- Klik tombol
Save, akan muncul jendelaUnivariate: Save. Sesuaikan isiannya sebagai berikut.- Residuals:
Studentized(dicentang).
- Residuals:
- Klik tombol
Continue, kemudian klik tombolOK. Hasilnya akan muncul pada jendelaoutputdandataset. Abaikan dulu jendelaoutputdan fokus pada jendeladataset. - Pada jendela
dataset, muncul kolom baru bernamaSRE_1. Kemudian pilih menuTransform > Compute Variable. Pada jendelaCompute Variable, sesuaikan isiannya sebagai berikut.- Target Variable:
ABS_SRE_1. - Numeric Expression:
ABS(SRE_1).
- Target Variable:
- Klik tombol
OKdan kembali ke jendeladataset. Muncul kolom baru bernamaABS_SRE_1. - Pilih menu
Graphs > Chart Builder. Apabila muncul jendela dialog, klikOK. - Pada jendela
Chart Builder, tabGallery > Choose from:, pilihBoxplot. Klik 2x pada gambar1-D Boxplot, maka akan muncul pada kotakChart preview uses example data. - Masih di jendela
Chart Builder, pada kotakVariables, lakukan drag and drop variabelABS_SRE_1keX-Axis?yang terletak di kotakChart preview uses example data, kemudian Klik tombolOK. - Hasil akan muncul pada jendela
outputberupa gambar boxplot.
Tampilan output
Klik di sini untuk melihat output.

Interpretasi hasil
Pada boxplot, terlihat hanya ada 1 data yang muncul dengan nilai Absolute Studentized Residual (ABS*SRE) = 2. Data ini bukanlah outlier, karena data yang mengandung outlier adalah ketika nilai ABS_SRE lebih besar dari 3 (SRE > 3)1. Simpulannya, data tidak mengandung outlier sehingga asumsi ini terpenuhi.
Bagaimana jika terdapat outlier? Kita akan bahas pada tulisan selanjutnya.
Linearity
Uji asumsi yang ke-2 adalah linearity. Uji asumsi linearity bertujuan untuk memeriksa apakah hubungan antara variabel kovariat dan variabel terikat bersifat linier. Asumsi ini penting karena Ancova mengasumsikan bahwa efek variabel kovariat terhadap variabel terikat adalah konstan melintasi semua tingkat variabel kovariat. Jika asumsi ini tidak terpenuhi, hasil Ancova mungkin tidak valid, dan interpretasi dampak variabel kovariat dapat menjadi meragukan. Uji linearitas melibatkan penilaian pola sebaran titik antara variabel kovariat dan variabel terikat, baik melalui metode grafis maupun uji statistik. Jika ditemukan pola non-linear, peneliti dapat mempertimbangkan transformasi data atau penggunaan metode analisis alternatif yang lebih sesuai. Memeriksa asumsi linearitas menjadi langkah kritis dalam memastikan keakuratan hasil Ancova serta mendukung kesimpulan yang valid terkait pengaruh variabel kovariat pada variabel terikat. Untuk melakukan uji asumsi ini pada SPSS, langkah-langkahnya adalah sebagai berikut.
Prosedur input
- Masuk ke menu SPSS
Analyze > Regression > Linear. Pada jendelaLinear Regression, sesuaikan isiannya sebagai berikut.- Dependent:
posttest. - Independent(s):
pretest.
- Dependent:
- Cek pada bagian model regresi dengan menekan tombol
Model. PastikanSpecify ModeladalahFull factorial. Klik tombolContinue. - Klik tombol
OK. Akan muncul hasilnya pada jendelaoutput. Fokus pada tabelModel SummarydanCoefficients. - Untuk menghasilkan grafik linearitas antar variabel, masuk ke menu
Graphs > Legacy Dialogs > Scatter/Dot. - Pilih
Simple Scatter, kemudian klik tombolDefine. Pada jendelaSimple Scatterplot, sesuaikan isiannya sebagai berikut.- Y Axis:
posttest. - X Axis:
pretest.
- Y Axis:
- Klik tombol
OK, akan muncul hasil berupa scatter plot pada jendelaoutput. - Untuk memunculkan garis linear di gambar scatter plot, pada jendela
output, klik 2 kali di gambar scatter plot untuk memunculkan jendelaChart Editorkemudian klik tombolAdd Fit Line at Totalyang terletak pada menu bar di atas gambar, akan muncul jendelaProperties. - Pada jendela
Properties, tabFit Line, kotakFit Method, pilihLinear. Kemudian klik tombolClose, dan tutup jendelaChart Editor. Akan muncul gambar scatter plot berisikan garis linear dan nilai R2-nya.
Tampilan output
Klik di sini untuk melihat output tabel.

Klik di sini untuk melihat output scatter plot.

Interpretasi hasil
Pada tabel Model Summary, terlihat bahwa nilai R2 = 0,612 yang artinya model linier dinilai cukup baik untuk memperkirakan pengaruh dengan persentasenya sebesar 61,2%. Pada tabel Coefficients, terlihat bahwa nilai koefisien sebesar 0,722 dengan Sig. sebesar 0,00. Jika nilai koefisien tidak nol dan Sig. kurang dari 0,05, maka terdapat hubungan linier antara kovariat dan variabel terikat2. Oleh karena itu, uji asumsi linearity terpenuhi.
Hal ini diperjelas dengan gambar scatter plot, di mana terlihat data tersebar acak. Data pada scatter plot yang terlihat acak (tidak membentuk pola tertentu) menandakan hubungan antara kovariat dan variabel terikat adalah linear3.
Bagaimana jika data tidak linier atau uji asumsi linearity tidak terpenuhi? Kita akan bahas pada tulisan selanjutnya.
Homogeneity of regression slopes
Uji asumsi yang ke-3 adalah Homogeneity of regression slopes. Uji asumsi ini bertujuan untuk memastikan bahwa pengaruh variabel kovariat terhadap variabel terikat memiliki kemiringan yang seragam di antara kelompok perlakuan yang berbeda. Jika hubungan tersebut tidak seragam, ini dapat menunjukkan bahwa efek kovariat bervariasi di antara kelompok perlakuan, yang dapat mengancam validitas analisis Ancova. Oleh karena itu, uji ini membantu memastikan bahwa asumsi homogenitas regresi terpenuhi sebelum melanjutkan analisis Ancova. Untuk melakukan uji asumsi ini pada SPSS, langkah-langkahnya adalah sebagai berikut.
Prosedur input
- Masuk ke menu SPSS
Analyze > General Linear Model > Univariate. Pada jendelaUnivariate, sesuaikan isiannya sebagai berikut.- Dependent Variable:
posttest. - Fixed Factor(s):
VLEs. - Covariate(s):
pretest.
- Dependent Variable:
- Klik tombol
Model, akan muncul jendelaUnivariate: Model, sesuaikan isiannya sebagai berikut.- Specify Model:
build terms. - Factors & Covariates:
VLEs,pretest. - Model:
VLEs,pretest,pretest*VLEs.
- Specify Model:
- Klik tombol
Continue. - Klik tombol
Save, akan muncul jendelaUnivariate: Save. Sesuaikan isiannya sebagai berikut.- Residuals:
Studentized(hilangkan centang). Jika secara default tidak dicentang, maka abaikan langkah ini.
- Residuals:
- Klik tombol
OK, akan muncul hasil berupa tabelTests of Between-Subjects Effectspada jendelaoutput. - Untuk menghasilkan grafik linearitas antar variabel, masuk ke menu
Graphs > Legacy Dialogs > Scatter/Dot. - Pilih
Simple Scatter, kemudian klik tombolDefine. Pada jendelaSimple Scatterplot, sesuaikan isiannya sebagai berikut.- Y Axis:
posttest. - X Axis:
pretest. - Set Markers by:
VLEs.
- Y Axis:
- Klik tombol
OK, akan muncul hasil berupa scatter plot pada jendelaoutput. - Untuk memunculkan garis linear pada masing-masing kelompok variabel bebas di gambar scatter plot, pada jendela
output, klik 2 kali di gambar scatter plot untuk memunculkan jendelaChart Editorkemudian klik tombolAdd Fit Line at Subgroupsyang terletak pada menu bar di atas gambar, akan muncul jendelaProperties. - Pada jendela
Properties, tabFit Line, kotakFit Method, pilihLinear. Kemudian klik tombolClose, dan tutup jendelaChart Editor. Akan muncul gambar scatter plot berisikan garis linear dan nilai R2 untuk masing-masing kelompok pada variabel bebas.
Klik di sini untuk melihat detail langkah nomor 2.

Tampilan output
Klik di sini untuk melihat output tabel.
Klik di sini untuk melihat output scatter plot.

Interpretasi hasil
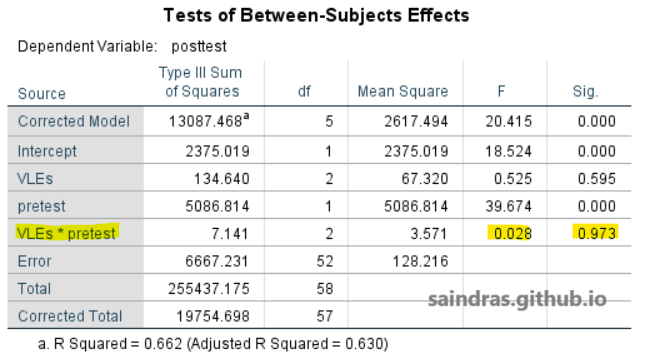
Pada tabel Tests of Between-Subjects Effects, terlihat nilai F = 0,028 dan nilai Sig. = 0,973 pada baris VLEs*pretest. Jika nilai Sig. lebih besar dari 0,05, maka tidak ada perbedaan kemiringan secara signifikan di antara kelompok perlakuan3. Hal ini diperjelas dengan gambar scatter plot, di mana terlihat garis linear antar variabel cenderung paralel yang menunjukkan tidak ada perbedaan kemiringan antar kelompok dalam variabel bebas3. Simpulannya, kemiringan garis ketiga kelompok sangat mirip, menunjukkan bahwa hubungan antara posttest dan pretest sangat mirip pada ketiga kelompok. Oleh karena itu, asumsi ini terpenuhi.
Jika asumsi homogenitas lereng regresi terpenuhi, maka F-statistik yang dihasilkan dapat diasumsikan memiliki distribusi F yang sesuai3. Sebaliknya, jika asumsinya tidak terpenuhi, maka artinya statistik F yang dihasilkan dievaluasi berdasarkan distribusi yang berbeda dari distribusi sebenarnya. Akibatnya, tingkat kesalahan tes Tipe I meningkat dan kemampuan untuk mendeteksi efek tidak maksimal. Hal ini terutama berlaku ketika ukuran kelompok tidak sama dan ketika kemiringan regresi standar berbeda lebih dari 0,4.
Jika asumsi Homogeneity of regression slopes tidak terpenuhi, maka dapat memodelkan variasi ini secara eksplisit menggunakan model linier bertingkat (multilevel linear models)3. Kita akan bahas pada tulisan selanjutnya.
Normality of residuals
Uji asumsi yang ke-4 adalah normality of residuals. Uji asumsi ini bertujuan untuk memeriksa sejauh mana residu dari model regresi memiliki distribusi normal. Residu yang memiliki distribusi normal menunjukkan bahwa asumsi normalitas terpenuhi, sehingga hasil analisis Ancova dapat diandalkan. Normality of residuals menjadi penting karena analisis inferensial, seperti uji hipotesis dan interval kepercayaan, membutuhkan asumsi distribusi normal pada residu. Jika distribusi residu tidak normal, hal ini dapat memengaruhi validitas hasil dan interpretasi analisis Ancova. Oleh karena itu, uji normality of residuals membantu memastikan bahwa asumsi distribusi normal pada residu terpenuhi untuk hasil analisis yang lebih akurat. Untuk melakukan uji asumsi ini pada SPSS, langkah-langkahnya adalah sebagai berikut.
Prosedur input
- Masuk ke menu SPSS
Analyze > General Linear Model > Univariate. Pada jendelaUnivariate, sesuaikan isiannya sebagai berikut.- Dependent Variable:
posttest. - Fixed Factor(s):
VLEs. - Covariate(s):
pretest.
- Dependent Variable:
- Cek kembali pada bagian
Model. PastikanSpecify ModeladalahFull factorial. - Klik tombol
Save, akan muncul jendelaUnivariate: Save. Sesuaikan isiannya sebagai berikut.- Residuals:
Unstandardized(dicentang). Pastikan jenis residu lainnya pada boxResidualstidak tercentang.
- Residuals:
- Klik tombol
Continue, kemudian klik tombolOK. Hasilnya akan muncul pada jendelaoutputdandataset. Abaikan dulu jendelaoutputdan fokus pada jendeladataset. - Pada jendela
dataset, muncul kolom baru bernamaRES_1. Masuk ke menuAnalyze > Descriptive Statistics > Explore. - Pada jendela
Explore, sesuaikan isiannya sebagai berikut.- Dependent list:
Residual for posttest [RES_1].
- Dependent list:
- Klik tombol
Plots, akan muncul jendelaExplore: Plots, sesuaikan isiannya sebagai berikut.- Descriptive:
Steam-and-leaf(hilangkan centang). - Descriptive:
Histogram(centang). - Centang pada bagian
Normality plots with tests.
- Descriptive:
- Klik tombol
Continue, kemudian klik tombolOK. Hasil akan muncul pada jendelaoutputberupa gambar histogram dan tabelTests of Normality. - Pada jendela
output, klik 2 kali pada gambar histogram, akan muncul jendelaChart Editor. - Pada jendela
Chart Editorklik menuShow Distribution Curve, akan muncul jendelaProperties. Pastikan pilihan pada kotakCurvesadalahNormal. Setelah itu tekan tombolClosedan tutup jendelaChart Editor. Kita akan melihat gambar histogram pada jendelaoutputdilengkapi dengan garis kurva normal.
Tampilan output
Klik di sini untuk melihat output tabel.

Klik di sini untuk melihat output histogram dengan garis kurva normal.

Interpretasi hasil
Pada tabel Tests of Normality, terlihat nilai Kolmogorov-Smirnov Statistic = 0,077 dengan nilai Sig. = 0.200. Terlihat juga nilai Shapiro-Wilk Statistic = 0,990 dengan nilai Sig. = 0.901. Nilai Sig. lebih besar dari 0,05. Hal ini menandakan data unstandardized residual berdistribusi normal. Oleh karena itu, uji asumsi normality of residuals terpenuhi.
Terdapat banyak asumsi normalitas yang keliru (miskonsepsi). Asumsi normalitas yang benar adalah mengacu pada sisa model (residu) yang terdistribusi secara normal, atau distribusi sampling dari parameter, bukan mengacu pada data itu sendiri3. Dalam kasus ini, kita menganalisis asumsi normalitas mengacu pada nilai absolute studentized residual dari model regresi, bukan mengacu pada nilai pretest atau posttest secara langsung.
Bagaimana jika data tidak normal atau uji asumsi normality of residuals tidak terpenuhi? Kita akan bahas pada tulisan selanjutnya.
Homogeneity of variances
Uji asumsi yang ke-5 adalah homogeneity of variances. Uji asumsi ini bertujuan untuk memastikan bahwa variabilitas dari residu regresi seragam di seluruh kelompok perlakuan. Homogenitas varian merupakan asumsi kritis yang perlu dipenuhi agar hasil analisis Ancova dapat diandalkan. Jika terdapat perbedaan yang signifikan dalam variabilitas antar kelompok perlakuan, hal ini dapat mempengaruhi validitas interpretasi hasil dan kesimpulan yang diambil dari analisis tersebut. Oleh karena itu, uji ini bertujuan untuk memverifikasi apakah homogenitas varian dapat diasumsikan, sehingga memastikan keabsahan hasil analisis Ancova. Untuk melakukan uji asumsi ini pada SPSS, langkah-langkahnya adalah sebagai berikut.
Prosedur input
- Masuk ke menu SPSS
Analyze > Compare Means > One-Way ANOVA, akan muncul jendelaOne-Way ANOVAkemudian sesuaikan isiannya sebagai berikut.- Dependen List:
Residual for posttest [RES_1]. - Factor:
VLEs.
- Dependen List:
- Klik tombol
Options, kemudian sesuaikan isiannya sebagai berikut.- Statistics:
Homogeneity of variance test(dicentang).
- Statistics:
- Klik tombol
Continue, lalu klik tombolOK, akan muncul tabelTest of Homogeneity of Variancespada jendela output.
Tampilan output
Klik di sini untuk melihat output tabel.
Interpretasi hasil
Hipotesis Levene’s Test adalah sebagai berikut.
- Hipotesis Nol (H0): tidak terdapat perbedaan yang signifikan dalam varians antar kelompok data, atau varians dari setiap kelompok data adalah sama (homogen).
- Hipotesis Alternatif (Ha): terdapat perbedaan yang signifikan dalam varians antar kelompok data (tidak homogen/heterogen).
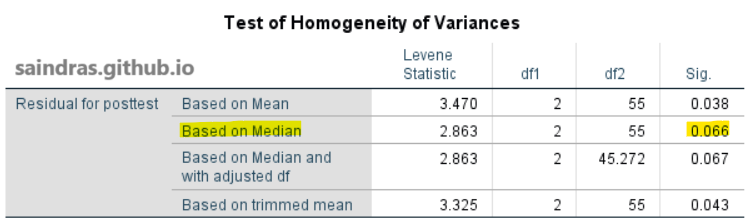
Jika nilai signifikansi Levene’s Test lebih besar dari 0,05, maka Hipotesis Alternatif ditolak, dan Hipotesis Nol diterima. Dengan kata lain, kita tidak memiliki cukup bukti statistik untuk menolak Hipotesis Nol dan asumsi homogeneity of variances terpenuhi3.
Pada tabel Test of Homogeneity of Variances, terlihat nilai Sig. = 0,066. Nilai ini lebih besar dari 0,05 yang artinya variabilitas atau dispersi dari kelompok-kelompok yang dibandingkan adalah sama atau tidak terdapat perbedaan signifikan dalam variabilitas antar kelompok. Oleh karena itu, asumsi homogeneity of variances terpenuhi.
Bagaimana jika uji asumsi homogeneity of variances tidak terpenuhi? Kita akan bahas pada tulisan selanjutnya.
Ancova satu jalur
Setelah semua uji asumsi terpenuhi, selanjutnya adalah melakukan perhitungan Ancova. Langkah-langkah Ancova pada SPSS adalah sebagai berikut.
Prosedur input
- Masuk ke menu SPSS
Analyze > General Linear Model > Univariate. Pada jendelaUnivariate, sesuaikan isiannya sebagai berikut.- Dependent Variable:
posttest. - Fixed Factor(s):
VLEs. - Covariate(s):
pretest.
- Dependent Variable:
- Cek kembali pada bagian
Model. PastikanSpecify ModeladalahFull factorial. - Cek kembali pada bagian
Save. Pastikan tidak ada yang tercentang pada kotakResiduals. - Klik tombol
Plots, akan muncul jendelaUnivariate: Profile Plots, sesuaikan isiannya sebagai berikut.- Factors:
VLEs. - Plots:
VLEs.
- Factors:
- Klik tombol
Continue. - Pada jendela
Univariate, klik tombolEM Means, akan muncul jendelaUnivariate: Estimated Marginal Means, sesuaikan isiannya sebagai berikut.- Display Means for:
VLEs. - Centang pada pilihan
Compare main effects. - Confidence interval adjustment:
Bonferroni.
- Display Means for:
- Klik tombol
Continue. - Pada jendela
Univariate, klik tombolOK. Hasil akan muncul pada jendelaoutputberupa tabelTests of Between-Subjects Effects,Estimates, danPairwise Comparisons, serta hasil berupa gambar plot terkait Estimated Marginal Means of posttest.
Klik di sini untuk melihat detail langkah nomor 4.
Tampilan output
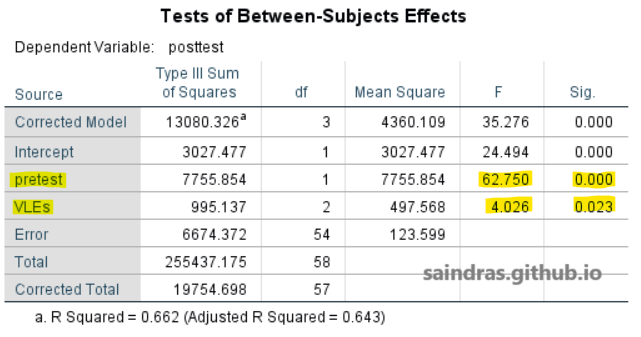
Klik di sini untuk melihat output tabel Tests of Between-Subjects Effects.
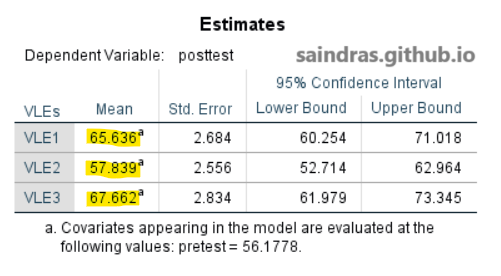
Klik di sini untuk melihat output tabel Estimates.
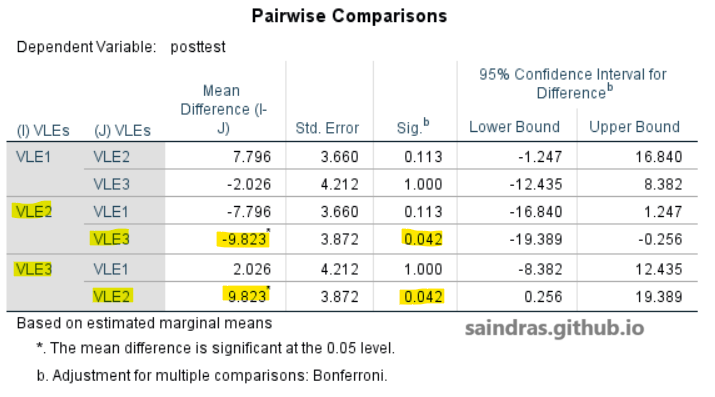
Klik di sini untuk melihat output tabel Pairwise Comparisons.
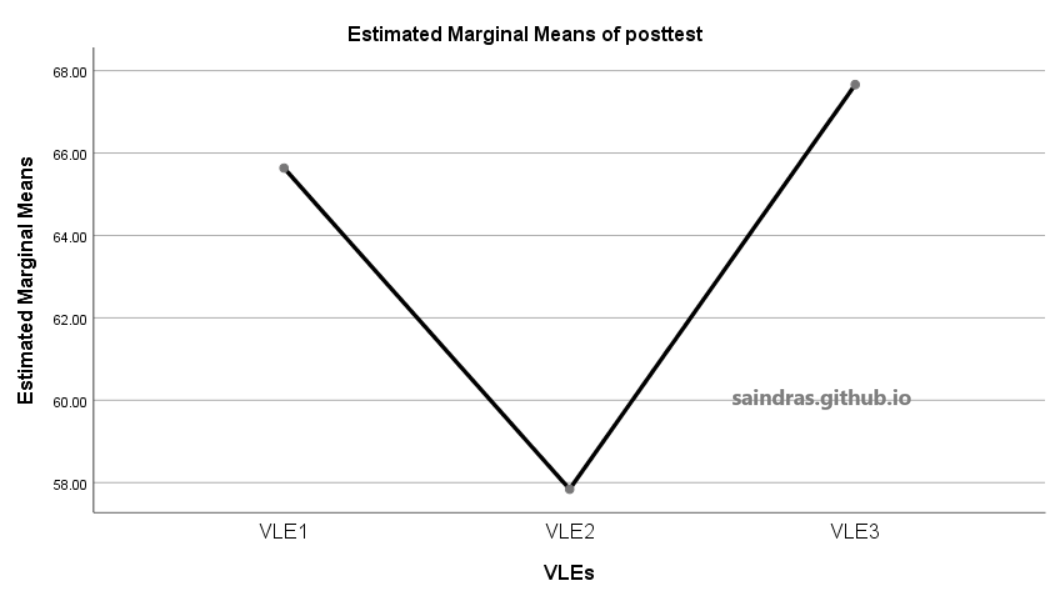
Klik di sini untuk melihat output plot Estimated Marginal Means of posttest.
Interpretasi hasil
Pada tabel Tests of Between-Subjects Effects, terlihat nilai signifikansi dari variabel pretest kurang dari 0,05 (F = 62,75; Sig. = 0,000) dan nilai dari variabel VLEs kurang dari 0,05 (F = 4,026; Sig. = 0,023). Nilai-nilai tersebut menjawab hipotesis penelitian yang pertama yakni terdapat pengaruh yang signifikan VLEs terhadap prestasi belajar dikontrol oleh pretest.
Pada tabel Estimates, terlihat rata-rata nilai posttest setelah dikontrol oleh nilai pretest dari kelompok VLE3 lebih tinggi dari VLE2 dan VLE1, serta VLE1 lebih tinggi dari VLE2. (VLE3 > VLE1 > VLE2). Hasil ini juga dapat dilihat dalam bentuk gambar diagram plot Estimated Marginal Means of posttest.
Pada tabel Pairwise Comparisons, terlihat bahwa perbedaan antara VLE3 dan VLE2 adalah signifikan (Sig. = 0,042; Sig. < 0,05). Perbedaan antara VLE3 dan VLE1 tidak signifikan (Sig. = 1,000; Sig. > 0,05). Perbedaan antara VLE2 dan VLE1 tidak signifikan (Sig. = 0,113; Sig. > 0,05). Hasil-hasil ini sekaligus menjawab hipotesis penelitian yang kedua yakni,
- Tidak terdapat perbedaan signifikan antara VLE1 dan VLE2 terhadap prestasi belajar dikontrol oleh pretest.
- Tidak terdapat perbedaan signifikan antara VLE1 dan VLE3 terhadap prestasi belajar dikontrol oleh pretest.
- Terdapat perbedaan signifikan antara VLE2 dan VLE3 terhadap prestasi belajar dikontrol oleh pretest.
Sitasi dokumen ini
Santyadiputra, G. S., Purnomo, & Juniantari, M. (2023, November 29). Ancova satu jalur menggunakan SPSS. GitHub. https://doi.org/10.5281/zenodo.10219479
![]()
Referensi
Pardoe, I. (2021). Applied regression modeling (3rd ed). Wiley. ↩︎
Klopper, J. (2022). Analysis of covariance using Python. YouTube. https://www.youtube.com/watch?v=FhZB1oGVrYc. ↩︎
Field, A. (2017). Discovering Statistics Using IBM SPSS Statistics (5th ed.). SAGE Publications. ↩︎ ↩︎2 ↩︎3 ↩︎4 ↩︎5 ↩︎6 ↩︎7